En quoi les risques spécifiques à l’IA diffèrent-ils des risques des logiciels traditionnels ?
Les risques propres à l’intelligence artificielle diffèrent de ceux des logiciels traditionnels principalement en raison de la manière dont les systèmes d’IA sont conçus, de leur complexité et de leur forte intégration dans des dynamiques sociales. Alors que les logiciels traditionnels reposent sur du code explicite écrit par des humains, les systèmes d’IA s’appuient souvent sur un apprentissage fondé sur les données, ce qui introduit plusieurs défis nouveaux.
Les principales différences identifiées sont les suivantes :
1. Dépendance aux données et nature dynamique
Évolution des données d’entraînement : les systèmes d’IA sont entraînés sur des données susceptibles d’évoluer de manière significative et imprévisible au fil du temps, ce qui peut affecter leur fonctionnement de manière difficile à comprendre.
Perte de contexte : les jeux de données utilisés pour l’entraînement peuvent devenir déconnectés de leur contexte initial ou devenir obsolètes par rapport aux conditions réelles de déploiement.
Dérive (drift) : les systèmes d’IA nécessitent une maintenance plus fréquente en raison de la dérive des données, des modèles ou des concepts, c’est-à-dire lorsque les propriétés statistiques des données d’entrée évoluent dans le temps.
2. Complexité et manque de transparence
Nombre de points de décision : les systèmes d’IA peuvent contenir des milliards, voire des billions de points de décision, ce qui les rend bien plus complexes que les logiciels traditionnels.
Manque d’interprétabilité : les systèmes d’IA sont souvent « opaques », ce qui signifie qu’il est difficile d’expliquer comment ou pourquoi une décision spécifique a été prise.
Propriétés émergentes : les modèles à grande échelle peuvent présenter des comportements émergents, rendant leurs modes de défaillance beaucoup plus difficiles à anticiper que ceux des logiciels classiques.
3. Nature socio-technique et biais
Influence sociétale : les risques liés à l’IA sont intrinsèquement socio-techniques, résultant de l’interaction entre le code technique et des facteurs sociaux, tels que les personnes qui exploitent le système ou le contexte dans lequel il est déployé.
Biais nuisibles : contrairement aux logiciels traditionnels, l’IA peut plus facilement amplifier, perpétuer ou accentuer des biais systémiques, computationnels ou cognitifs humains, entraînant des résultats inéquitables.
4. Défis en matière de sécurité et de tests
Surfaces d’attaque spécifiques : les systèmes d’IA sont vulnérables à des attaques spécifiques que les cadres traditionnels ne couvrent pas entièrement, telles que l’empoisonnement des données, les exemples adversariaux ou l’extraction de modèles.
Limites des tests : les méthodes de test des logiciels traditionnels sont souvent insuffisantes pour l’IA, car ces systèmes ne sont pas soumis aux mêmes contrôles stricts que le développement logiciel classique. Il est parfois même difficile de déterminer ce qu’il convient de tester.
5. Perception et interaction humaines
Surconfiance : les utilisateurs ont tendance à percevoir les systèmes d’IA comme plus objectifs ou plus performants que les logiciels classiques, ce qui peut entraîner une confiance excessive et un manque d’intervention en cas d’erreur.
Perte de contexte : la transformation de phénomènes humains complexes en modèles mathématiques pour l’IA entraîne souvent une perte de contexte, ce qui complique la gestion des impacts individuels et sociétaux.
Quels sont les risques liés à l'intelligence artificielle (IA) ?
1. Les biais algorithmiques et la discrimination
C'est l'un des risques les mieux documentés. Un système d'IA n'est que le reflet des données sur lesquelles il a été entraîné : si ces données comportent des biais, le système les reproduira et les amplifiera dans ses décisions, conduisant potentiellement à des discriminations.
Un exemple emblématique est celui de l'algorithme de recrutement d'Amazon, dont les analystes ont constaté en 2018 que le programme pénalisait les candidatures féminines, car il avait été entraîné sur des bases de CV où les hommes étaient historiquement surreprésentés aux postes techniques.
Au-delà du recrutement, les systèmes de diagnostic médical peuvent retourner des résultats moins précis pour les populations historiquement sous-représentées, et les outils de police prédictive peuvent cibler de manière disproportionnée certaines communautés marginalisées.
2. Les atteintes à la vie privée et à la protection des données
L'IA peut avoir un grave impact sur le droit à la vie privée. Elle peut être employée dans des appareils de reconnaissance faciale ou pour profiler et traquer des personnes en ligne. Elle peut également combiner différentes données afin de créer une nouvelle donnée sur une personne et produire un résultat inattendu.
Sur le plan technique, les grands modèles de langage nécessitent d'immenses volumes de données d'entraînement. Les données collectées par moissonnage du web le sont souvent sans le consentement des utilisateurs et peuvent contenir des données identifiantes.
3. La désinformation, les deepfakes et la manipulation démocratique
L'IA pourrait aussi représenter un risque pour la démocratie : on la tient pour responsable de la création des « chambres à écho » sur le web, ne proposant à un individu que du contenu qui lui est agréable. Elle est également employée dans la création de deepfakes. Ces éléments contribuent à polariser l'espace public et peuvent avoir des conséquences politiques majeures.
La DGSI illustre ce risque de manière très concrète : un responsable d'un site industriel français a reçu un appel en visioconférence d'une personne se présentant comme le dirigeant du groupe, dont l'apparence physique et la voix correspondaient parfaitement à celles de ce dernier. Il s'agissait en réalité d'une tentative d'escroquerie par hypertrucage (deepfake), associant le visage et la voix du dirigeant grâce à l'IA.
4. Les risques pour la cybersécurité
Des acteurs malveillants peuvent exploiter l'IA pour lancer des cyberattaques : cloner des voix, générer de fausses identités et des e-mails de phishing convaincants, dans l'intention d'escroquer, de pirater ou de voler des identités. Selon IBM, le coût moyen mondial d'une violation de données s'élevait à 4,88 millions de dollars en 2024, et seulement 24 % des initiatives d'IA générative sont sécurisées.
Des attaquants peuvent également manipuler les données d'entrée d'un système d'IA — par exemple en modifiant subtilement une image — pour tromper l'algorithme et provoquer des erreurs ou des comportements dangereux dans des systèmes critiques comme les véhicules autonomes ou les dispositifs médicaux. C'est ce qu'on appelle les attaques par exemples contradictoires.
5. L'opacité des systèmes : le problème de la « boîte noire »
Les décisions prises par certains systèmes d'IA sont qualifiées de « boîtes noires », difficiles à comprendre ou à remettre en cause par les utilisateurs, ce qui complique la prise de décision éclairée et peut réduire la confiance.
Ce problème d'explicabilité est directement lié à la responsabilité juridique : en cas de litige, l'utilisation de l'IA risque de compliquer la résolution du contentieux, notamment si l'organisation ne parvient pas à démontrer la transparence ou la conformité du traitement des données, ni à justifier clairement les prises de décisions automatisées devant les instances légales concernées.
6. Les hallucinations et la fiabilité des informations
Les hallucinations, c'est-à-dire des erreurs ou des inventions produites par l'IA, peuvent avoir des conséquences graves si elles ne sont pas détectées et corrigées : prise de décision stratégique inadaptée, rapport financier erroné, contrat non conforme ou désinformation.
Les systèmes d’IA introduisent également des risques liés à la qualité des données. La fiabilité des résultats dépend directement de la qualité, de la représentativité et de l’actualité des données utilisées. Des données incomplètes, biaisées ou obsolètes peuvent conduire à des résultats incorrects, compromettant la pertinence des décisions prises et la confiance dans les systèmes.
7. L'impact sur l'emploi et la transformation du marché du travail
L'un des risques majeurs de l'IA est l'automatisation des tâches répétitives et analytiques, qui remet en question de nombreux emplois traditionnellement occupés par des humains, principalement dans les secteurs de la production industrielle, de la logistique, du commerce de détail et des services administratifs.
8. Les risques environnementaux
Un autre risque souvent négligé concerne l’impact environnemental des systèmes d’IA. Le développement, l’entraînement et le déploiement de modèles, en particulier les modèles de grande taille, nécessitent des ressources informatiques considérables, impliquant une consommation importante d’énergie et d’infrastructures. L’entraînement d’un modèle peut mobiliser des centres de données pendant plusieurs jours, voire plusieurs semaines, avec une empreinte carbone significative liée à la production d’électricité, souvent encore dépendante d’énergies fossiles dans certaines régions.
9. Les risques systémiques des modèles d'IA à usage général (GPAI)
Certains modèles d'IA à usage général, capables d'effectuer un large éventail de tâches et devenus la base de nombreux systèmes d'IA dans l'UE, pourraient porter des risques systémiques s'ils sont très puissants ou très répandus.
10. Les risques liés à la propriété intellectuelle
Les systèmes d’IA, en particulier ceux fondés sur des modèles génératifs, reposent sur de vastes ensembles de données d’entraînement dont l’origine et les droits associés ne sont pas toujours clairement identifiés. Cela soulève des questions complexes quant à l’utilisation de contenus protégés par le droit d’auteur, notamment lorsque des œuvres, textes, images ou codes ont été utilisés sans autorisation explicite. En aval, les contenus générés par l’IA peuvent eux-mêmes reproduire ou s’inspirer fortement d’œuvres existantes, exposant les organisations à des risques de contrefaçon ou de violation de droits de propriété intellectuelle.
En synthèse, les risques liés à l'IA se déploient sur quatre plans interdépendants : individuel (discrimination, vie privée), organisationnel (cyberattaques, responsabilité juridique), sociétal (démocratie, emploi) et systémique (sécurité des infrastructures critiques).
Comment gérer ces risques avec une plateforme comme Dastra ?
Une gouvernance rigoureuse, combinant conformité réglementaire, transparence algorithmique et supervision humaine effective, est aujourd'hui indispensable pour toute organisation déployant des systèmes d'IA.
Pour gérer efficacement ces risques spécifiques à l’IA, les organisations doivent adopter une approche structurée et continue. Des solutions comme Dastra permettent justement d’opérationnaliser cette gestion à travers des modules dédiés.
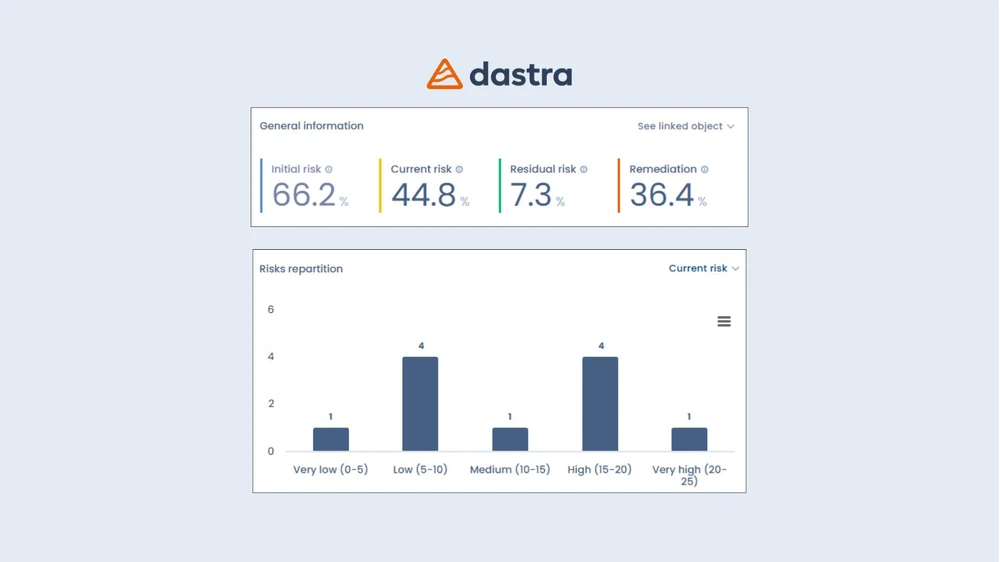
Le module de gestion des risques permet d’identifier, qualifier et suivre les risques liés aux systèmes d’IA, en intégrant des notions comme la dérive des modèles, les biais ou les vulnérabilités spécifiques.
En parallèle, le module Compliance intègre des référentiels comme le NIST AI RMF, en traduisant ses principes en exigences concrètes, tests et contrôles à mettre en place.
Cette approche permet de passer d’une compréhension théorique des risques à une gestion opérationnelle, avec des preuves de conformité, un suivi continu et une capacité à démontrer la maîtrise des risques auprès des parties prenantes et des régulateurs.